While supercomputers are traditionally being used in physics, material science and advanced chemistry, the Spresso project entails the very first formal cooperation between the Luxembourgish supercomputer MeluXina, the Bibliothèque nationale du Luxembourg and an interdisciplinary team of researchers of the Centre for Contemporary and Digital History (C²DH) and the Department of Computer Science of the University of Luxembourg, to explore the automatic enhancement of 20th century historical newspaper photography at a large scale through deep learning algorithms.
For years, press photography has played an integral role in shaping the image of countries, humans and events in the minds of newspaper readers all over the world. As such, these images provide an invaluable source for historians. Newspaper photos were printed using a process called half-toning and its characteristic dot pattern. The Spresso project is focused on digital copies of these half-toned images which were provided by the impresso project. Impresso is a cooperation between the C²DH at the University of Luxembourg, the EPFL in Lausanne and the University of Zurich as well as a broad range of archives, libraries and newspapers in Luxembourg and Switzerland. Spresso set itself the goal to make this treasure trove of images more accessible and usable for modern research approaches.
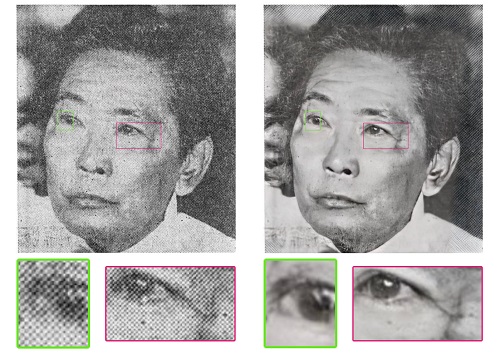
By applying a super-resolution algorithm based on deep learning models to the scanned half-tone images, Spresso has created new synthetic images from the source material with an often surprising degree of detail, eliminating the previously existing patterns that degenerated the image quality.
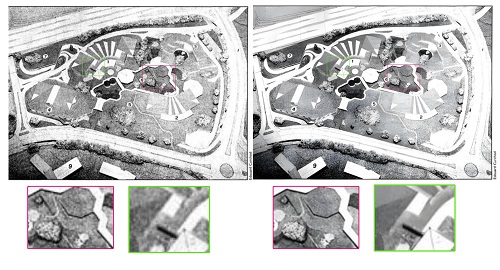
Starting with an initial set of 10,000 images and under the guidance of Prof. Luis Leiva, Dany Pais da Silva, a former student of the Bachelor in Computer Science, tested different super resolution algorithms and implemented a prototype pipeline for the conversion of the historic images on the University’s High Performance Computing facilities. With the support of LuxProvide engineers, the team was able to transfer the process to the new MeluXina supercomputer thereby scaling it up to apply it to more than 3 million images. “Working with MeluXina and the engineers at LuxProvide in an interdisciplinary project was an excellent opportunity for me to enhance my skills in working with big data”, reported Dany Pais da Silva. Interestingly, the hardest part was to download the data, not the computing power required to process it. “Getting access to the raw images has been a challenge for us, since we had to transfer them from their original source to MeluXina and then back to the University premises’‘, explains Prof. Luis Leiva.
The new dataset will be fed back into the Impresso application in the future to provide historians and the general public with the enhanced image quality. Historians Estelle Bunout and Marten Düring state: “Deep Learning provides great opportunities for digital history. Synthetic data generated by deep learning offers exciting opportunities to enter dialogues between human reasoning and computational analysis. But they also raise fundamental new questions regarding existing notions of authenticity and the reliability of the historical record. The Spresso project will become a point of departure for us to explore to which extent algorithmically modified images will improve further enrichment, e.g. object detection and identification.”
Lars Wieneke, Head of the Digital Research Infrastructure at the C²DH adds: “Thanks to the work of Dany Pais da Silva and Prof. Leiva as well as the team of LuxProvide, we can now work with a corpus of greatly improved images that we will challenge with advanced recognition algorithms to better understand if super resolution provides not only a perceived improvement of quality but also improves recognition rates for a variety of tasks such as object or person identification.”